Raphael Arkady Meyer

I recently got a Ph.D. from NYU Tandon School of Engineering, advised by Christopher Musco and part of the Algorithms and Foundations Group.
I research problems in mathematical computing from the perspective of theoretical computer science.
In the summer of 2022, I visited Michael Kapralov's group at EPFL and Haim Avron's group at TAU.
Links: Google Scholar, dblp, Github, Zoom Room
My recent publications have looked at:
Fast Numerical Linear Algebra (preprint, preprint, SODA2024)
Active Learning on Linear Function Families (SODA2023, NeurIPS2020)
Of course, I am interested in problems beyond these areas, and if you want to work with me on a problem, send me an email:
News
 I'll be joining Caltech as a postdoc in Joel Tropp's group this fall!
I'll be joining Caltech as a postdoc in Joel Tropp's group this fall!I've been awarded the Pearl Brownstein Doctoral Research Award (i.e. best dissertation award) for my research! Big thanks to the Tandon CSE department for awarding this to me, and congrats to the other awardees, Aecios and Mengwei!
I gave a talk at the Center for Communications Research on Trace Estimation and Kronecker-Trace Estimation.
April 2024
I just successfully defended my thesis, on April 16th 2024! See details about my talk here: link.
March 2024
The Responsible AI Lab at NYU Tandon (who I have been a part of for the past two years) wrote a spotlight on me! Thanks to Caterina and the R/AI team for writing this up. See the short interview here: link.
January 2024
I presented my work on Trace Estimation and Low-Rank Approximation at the Mahoney Group at UC Berkeley.
I presented my work on Krylov methods at SODA 2024.
November 2023
New preprint on arXiv: Algorithm-Agnostic Low-Rank Approximation of Operator Monotone Matrix Functions.
I gave a talk on Krylov methods at the Conference on Fast Direct Solvers at Purdue University in November.
I gave a talk at UChicago on Trace Estimation and Kronecker-Trace Estimation on November 1st.
October 2023
Paper accepted at SODA 2024: On the Unreasonable Effectiveness of Single Vector Krylov Methods for Low-Rank Approximation!
I organized a minisymposium on The Matrix-Vector Complexity of Linear Algebra at the first ever SIAM-NNP conference!
Shyam Narayanan, Diana Halikias, William Swartworth, Tyler Chen, and myself were presenting at 8:30am on Sunday. What a stacked lineup! See the details here: link.
September 2023
New preprint on arXiv: Hutchinson’s Estimator is Bad at Kronecker-Trace-Estimation.
May 2023
New preprint on arXiv: On the Unreasonable Effectiveness of Single Vector Krylov Methods for Low-Rank Approximation.
March 2023
I gave two talks at the NYU / UMass Quantum Linear Algebra reading group.
I gave a talk at the BIRS Perspectives on Matrix Computations about my new work on Krylov methods.
January 2023
I presented Near-Linear Sample Complexity for Polynomial Regression at SODA 2023.
November 2022
I gave a talk at the TCS Seminar at Purdue in early November to present my new research on the role of block size in Krylov Methods.
October 2022
New paper accepted at SODA 2023: Near-Linear Sample Complexity for Polynomial Regression! I just gave a talk on it last week Friday at the Grad Student Seminar at CDS (at NYU).
September 2022
I gave a talk at GAMM ANLA on the role of block size in Krylov Methods for low-rank approximation. A preprint will be available very soon, but until then you can check out my slides for a preview! Slides
July 2022
I gave a talk at the SIAM Annual Meeting Minisymposium on Matrix Functions, Operator Functions, and Related Approximation Methods. Thanks to Heather, Andrew, and Ke for organizing!
June 2022
I'm going be presenting Hutch++ this summer at HALG2022, with both a short talk and a poster.
I'm traveling this summer! I'm first in London for HALG2022. Then I'm spending June visiting Haim Avron at TAU, and July visiting Michael Kapralov at EPFL. If you're in the same place at the same time, drop me a line!
May 2022
I recently organized a mini-conference for NYU CS Theory researchers to present their "Pandemic Papers" in-person. Thanks to everyone who showed up and made it a success! More details here
I'm honored to be awarded the Deborah Rosenthal, MD Award for Best Quals Examination in 2022, for my presentation Towards Optimal Spectral Sum Estimation in the Matrix-Vector Oracle Model.
April 2022
I'm honored to be a ICLR 2022 Highlighted Reviewer.
Publications
Algorithm-Agnostic Low-Rank Approximation of Operator Monotone Matrix Functions
in submission with David Persson and Christopher MuscoHutchinson's Estimator is Bad at Kronecker-Trace-Estimation[1]
in submission with Haim AvronOn the Unreasonable Effectiveness of Single Vector Krylov Methods for Low-Rank Approximation[2]
at SODA 2024 with Cameron Musco and Christopher MuscoNear-Linear Sample Complexity for Polynomial Regression[3]
at SODA 2023 with Cameron Musco, Christopher Musco, David P. Woodruff, and Samson ZhouFast Regression for Structured Inputs[4]
at ICLR 2022 with Cameron Musco, Christopher Musco, David P. Woodruff, and Samson ZhouHutch++: Optimal Stochastic Trace Estimation[5]
at SOSA 2021 with Cameron Musco, Christopher Musco, and David P. WoodruffThe Statistical Cost of Robust Kernel Hyperparameter Tuning[6]
at NeurIPS 2020 with Christopher MuscoOptimality Implies Kernel Sum Classifiers are Statistically Efficient[7]
at ICML 2019 with Jean HonorioCharacterizing Optimal Security and Round-Complexity for Secure OR Evaluation
at ISIT 2017 with Amisha Jhanji and Hemanta K. Maji
| [1] | Slides |
| [2] | Code available on github Slides using TCS language Slides using Applied Math language |
| [3] | Slides |
| [4] | Poster |
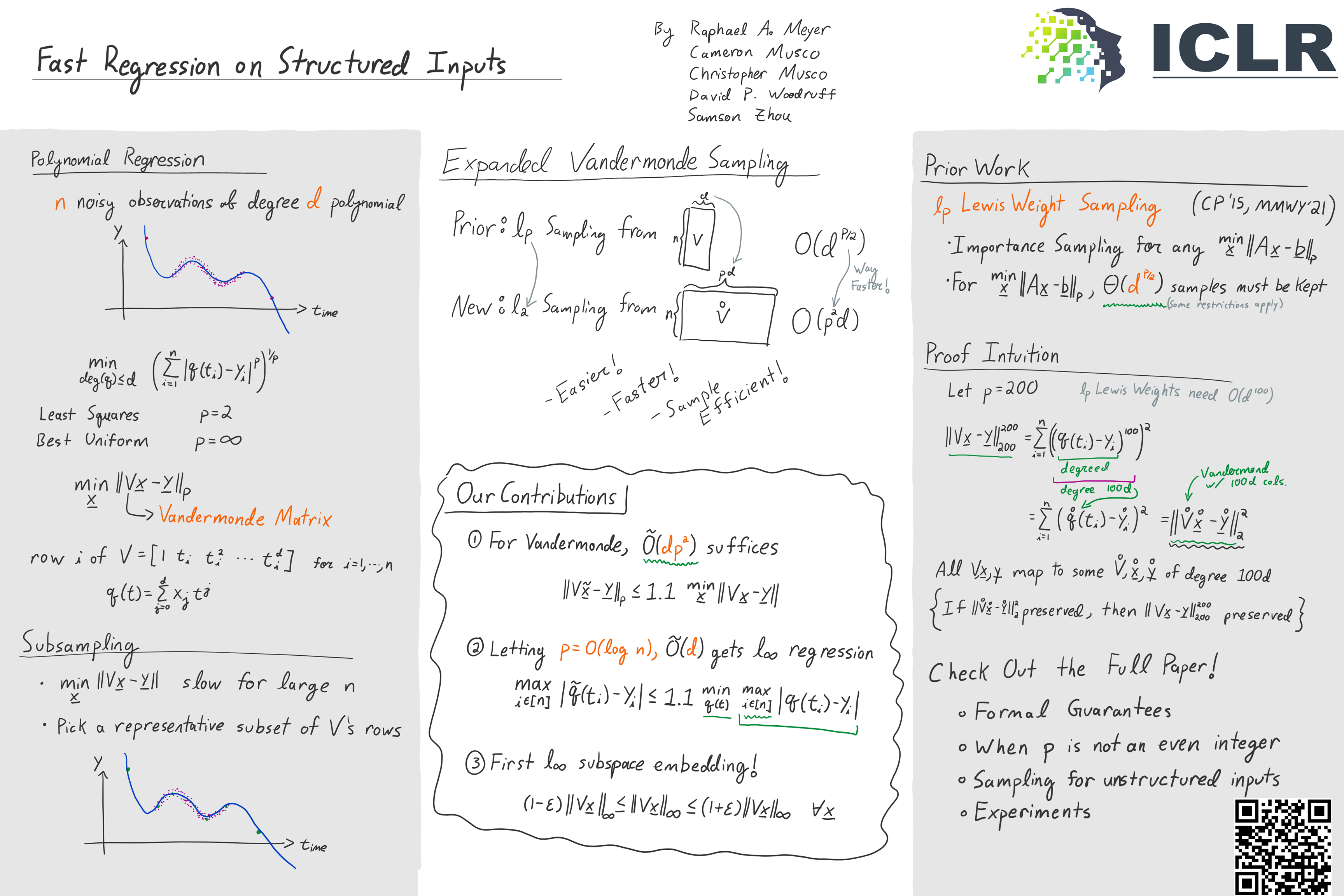{kind=link}
| [5] | Code available on github Landscape Poster Portrait Poster 4min Slides 12min Slides 25min Slides 35min Slides 1hr Slides |
| [6] | Slides |
| [7] | Poster Slides. |
Talks & Presentations
To date, I have presented every paper I published at the associated conference. This is a list of other talks or presentations I have given.
Optimal Trace Estimation and Sub-Optimal Kronecker-Trace Estimation
at Center for Communications Research.Optimal Trace Estimation and Algorithm-Agnostic funNystrom Guarantees
at UC Berkeley Mahoney Group Meeting.Optimal Trace Estimation and Sub-Optimal Kronecker-Trace Estimation
at U Chicago Theory Lunch.On the Unreasonable Effectiveness of Single Vector Krylov for Low-Rank Approximation
at BIRS workshop on Perspectives on Matrix Computations.On the Unreasonable Effectiveness of Single Vector Krylov for Low-Rank Approximation
at Purdue University TCS SeminarNear-Linear Sample Complexity for Polynomial Regression
at NYU CDS Student SeminarHutch++ and More: Towards Optimal Spectral Sum Estimation
at Matrix Functions, Operator Functions, and Related Approximation Methods, a minisymposium at SIAM Annual Meeting (AN22)Hutch++: Optimal Stochastic Trace Estimation
at John Hopkins University Theory SeminarLessons from Trace Estimation Lower Bounds: Testing, Communication, and Anti-Concentration[8]
at Computational Lower Bounds in Numerical Linear Algebra, a minisymposium at SIAM Annual Meeting (AN21)
| [8] | Slides available here. Video starts at 1:04:55 here. |
On the Unreasonable Effectiveness of Single Vector Krylov for Low-Rank Approximation[9]
Short Talk at Conference on Fast Direct SolversHutchinson's Estimator is Bad at Kronecker-Trace-Estimation[9]
Short Talk at SIAM-NNP 2022On the Unreasonable Effectiveness of Single Vector Krylov for Low-Rank Approximation[9]
Short Talk at GAMM ANLA 2022.Hutch++: Optimal Stochastic Trace Estimation[9]
Poster and Short Talk at HALG 2022.Chebyshev Sampling is Optimal for Lp Polynomial Regression[9]
Talk at NYU "Pandemic Presentations" 2022Hutch++: Optimal Stochastic Trace Estimation[9]
Poster at Wald(O) 2021.Optimality Implies Kernel Sum Classifiers are Statistically Efficient[9]
Poster at Midwest Theory Day 2019
| [9] | Assets available in the Publications section. |
Feature Importance Impossibility Theorems[10]
45-min-long talk at NYU RAI Reading GroupFairwashing SHAP (aka Interventional and Observational Shapley Values)[11]
45-min-long talk at NYU RAI Reading GroupThe Equivalence of Matrix-Vector Complexity in Quantum Computing, Part 2
1-hour-long talk at NYU/UMass Quantum Linear Algebra Reading GroupThe Equivalence of Matrix-Vector Complexity in Quantum Computing, Part 1
1-hour-long talk at NYU/UMass Quantum Linear Algebra Reading GroupHutch++: Optimal Stochastic Trace Estimation
1-hour-long talk at NYU VIDA RG Reading GroupIntroduction to Leverage Scores
1.5-hour-long talk at NYU Tandon Theory Reading GroupStrategies for Episodic Tabular & Linear MDPs
Two 1.5-hour-long talks at NYU Tandon Reinforcement Learning Reading GroupLagrangian Duality
Three 1.5-hour-long talks at NYU Tandon Theory Reading GroupIntroduction to Differential Entropy
1-hour-long talk at NYU CDS Reading Group on Information TheoryLower bounds on the complexity of stochastic convex optimization[12]
1-hour-long presentation of the paper Information-Theoretic Lower Bounds on the Oracle Complexity of Stochastic Convex Optimization by Agarwal et. al.
| [10] | Link to relevant paper here. |
| [11] | Link to relevant paper here. My slides available here. |
| [12] | Link to the original paper here. My slides available here. |
Teaching
I really enjoy teaching, and have been a TA for a few courses now:
Responsible Data Science, New York University, Spring 2024
Algorithmic Machine Learning and Data Science, New York University, Fall 2023
Responsible Data Science, New York University, Spring 2023
Algorithmic Machine Learning and Data Science, New York University, Fall 2020
Introduction to Machine Learning, New York University, Spring 2020
Introduction to the Analysis of Algorithms, Purdue University, Fall 2018
Service
Service outside of reviewing:
Organizer for the Minisymposium "The Matrix-Vector Complexity of Linear Algebra" at SIAM-NNP 2023
Organizer for NYU TCS "Pandemic Presentations" Day
Organizer for NYU Tandon Theory Reading Group
Service as a reviewer:
NeurIPS 2024 Reviewer
FOCS 2024 External Reviewer
IMA Journal of Numerical Analysis 2024 Reviewer
ICALP 2024 External Reviewer
ICML 2024 Reviewer
IJCAI 2024 Reviewer
ICLR 2024 Reviewer
NeurIPS 2023 Reviewer
TMLR 2023 Reviewer
ICLR 2023 Reviewer
SODA 2023 External Reviewer
NeurIPS 2022 Reviewer
ICML 2022 Reviewer
STOC 2022 External Reviewer
ICLR 2022 Reviewer*
NeurIPS 2021 Reviewer*
ISIT 2017 External Reviewer
* Denotes Highlighted / Outstanding Reviewer